Exchequer receipt roll: from transcript to spreadsheet
For the ‘Digital Humanities meets Medieval Financial Records: The Receipt Rolls of the Irish Exchequer’ project, I’m looking at ways to digitally encode English language calendars of the rolls and exploring ways to interrogate and visualise the data. One roll has already been transcribed and published, as discussed in an earlier post. Rather than starting with the TEI/XML, I opted to look at getting the details of payment into CSV (and Excel), since this is the type of format that researchers might use to explore the data. It is also a useful format to work with data analysis tools and to create some example visualisations.
I’ve created a collection of scripts to process and clean the data. One script goes through each line of the transcript, looking for details of interest, namely payments and a record of the daily sums. It ignores weekly, monthly, termly and other periodic totals.
- For each payment made, it records the details of the payment, membrane number, term, date, day, the geographic location or other entity they are categorised by, date, day, value in £.s.d. or marks, and the computed value in pence.
- A second CSV file tracks the daily sums entered by the exchequer clerk, recording the value in in £.s.d. or marks, and the computed value in pence.
A second script creates a CSV file that compares the daily sum value entered by the clerk, with a computed daily value using the pandas library, highlighting where they diverge. This was a useful exercise for finding errors:
- Lots of initial bugs in my script in parsing values and extracting data. The code now has several unit tests for checking my regex/parsing logic.
- Errors in the transcript. There were a small number which I corrected in the source text file.
- One error by the scribe (1 penny out!)
A third script parsing the details of the payment and attempts to extract people, places and keywords:
- I use the NLTK default Parts of Speech (POS) tagger, to tag the details of a payment, into personal nouns, nouns, prepositions, adjectives etc. I then fix obvious errors, such as marking ‘de’, ‘le’ and ‘fitz’ as foreign words.
- I use the NLTK RegexParser to look for patterns that match people and places. The fact the transcript is English and provides names and places in common patterns, we get reasonable results. Places are generally identified as pronouns that are after certain nouns and prepositions, e.g. ‘city of Cork’
- For keywords I just extract nouns with a few stop words removed, namely ‘divers’, ‘others’ and ‘persons’
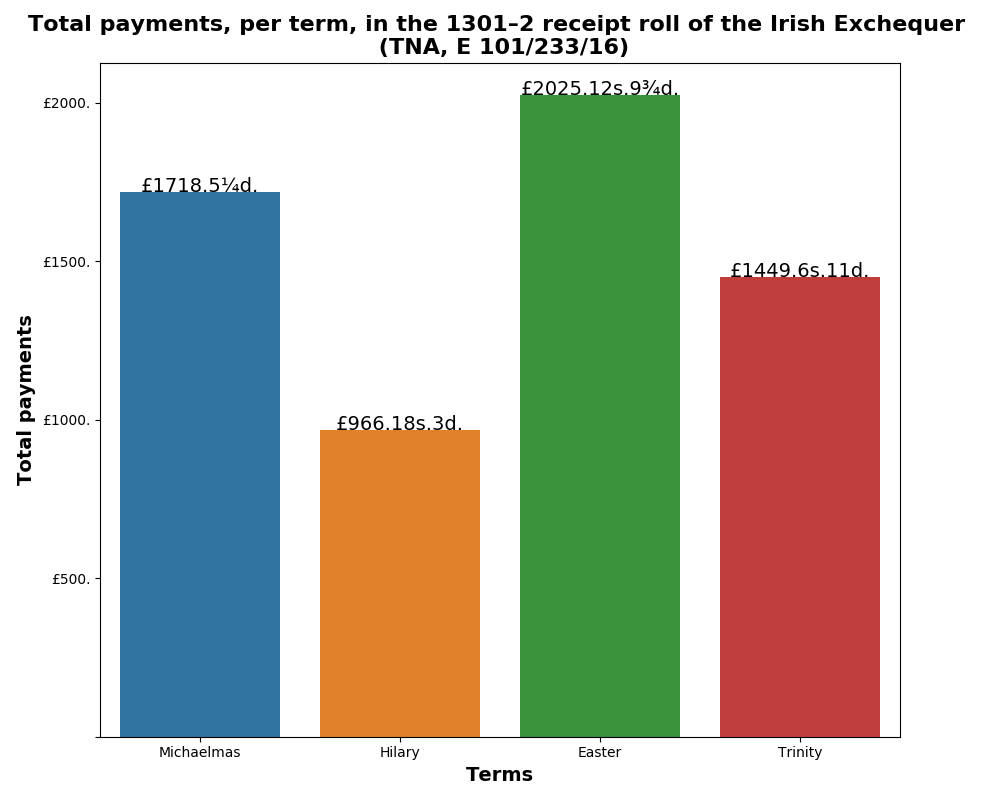
Anyway, the results mean that the data in the transcript is now in a tabular form, which means it can be queried using the pandas data library. For example, we can create the following bar plot which shows the total payments received by the Irish Exchequer for each financial term.
The code and data for the project is hosted here: https://github.com/ilrt/ReceiptRollE101